Takeaways: (1) M1 Max is powerful, deserves its price and outperforms some more expensive ARM64 servers. (2) The Always Free tier available on Oracle cloud can provide ARM64 servers with decent performance.
Just a quick compilation test amongst Apple M1 Max, AWS c6g.2xlarge, c6g.metal and Oracle Ampere (VM.Standard.A1.Flex).
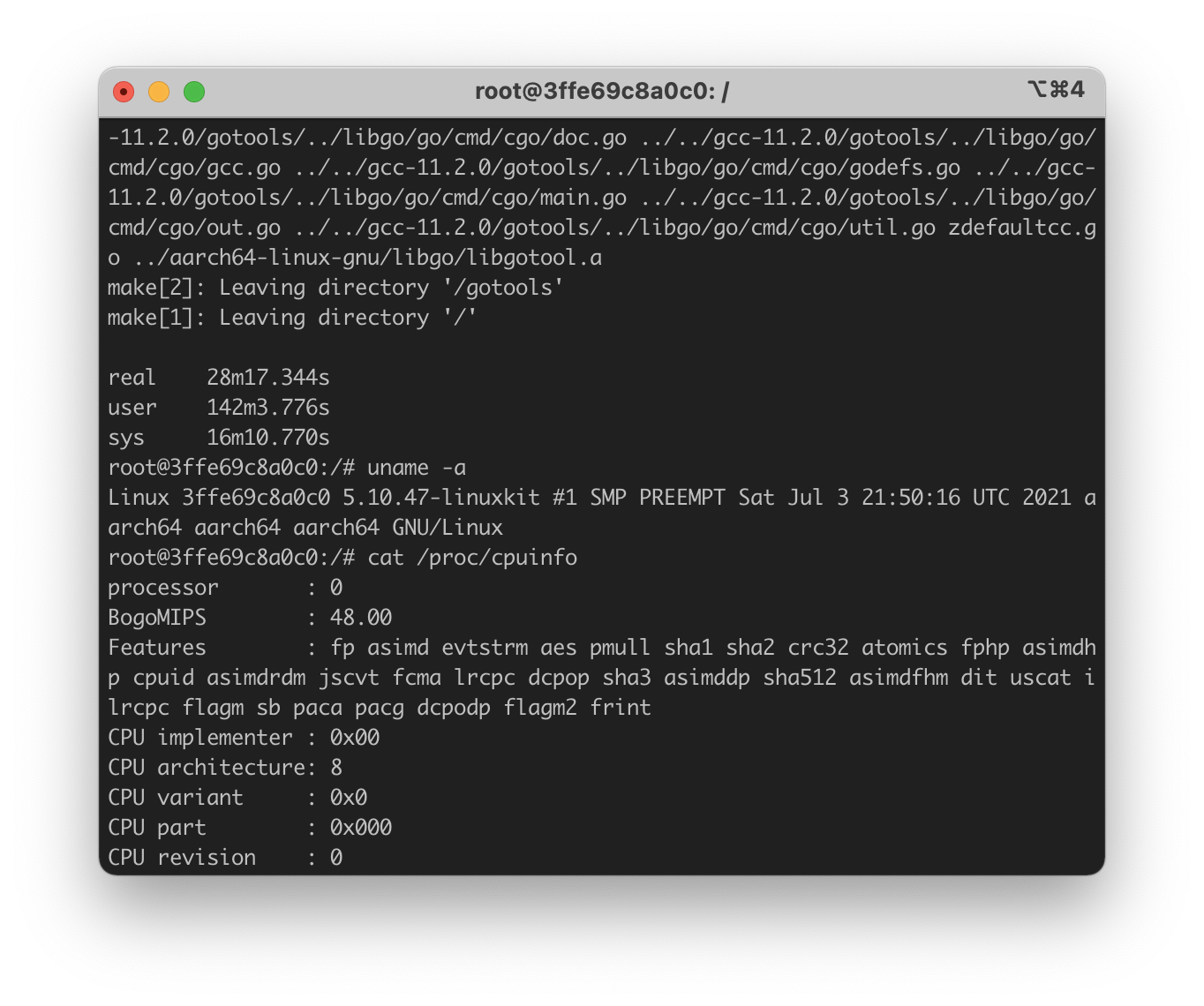
Hardware-wise, I'm using a MacBook Pro 14-inch with M1 Max (10 cores, 8 performance cores + 2 efficiency cores). The build is done in ARM64 docker with the arm64v8:ubuntu image. The docker engine can use 8 cores and 14 GB of RAM. It's worth noting that allocating 8 cores to the docker engine does not guarantee they are all performance cores. The core schedule is handled by macOS and there is no core pinning in recent macOS.
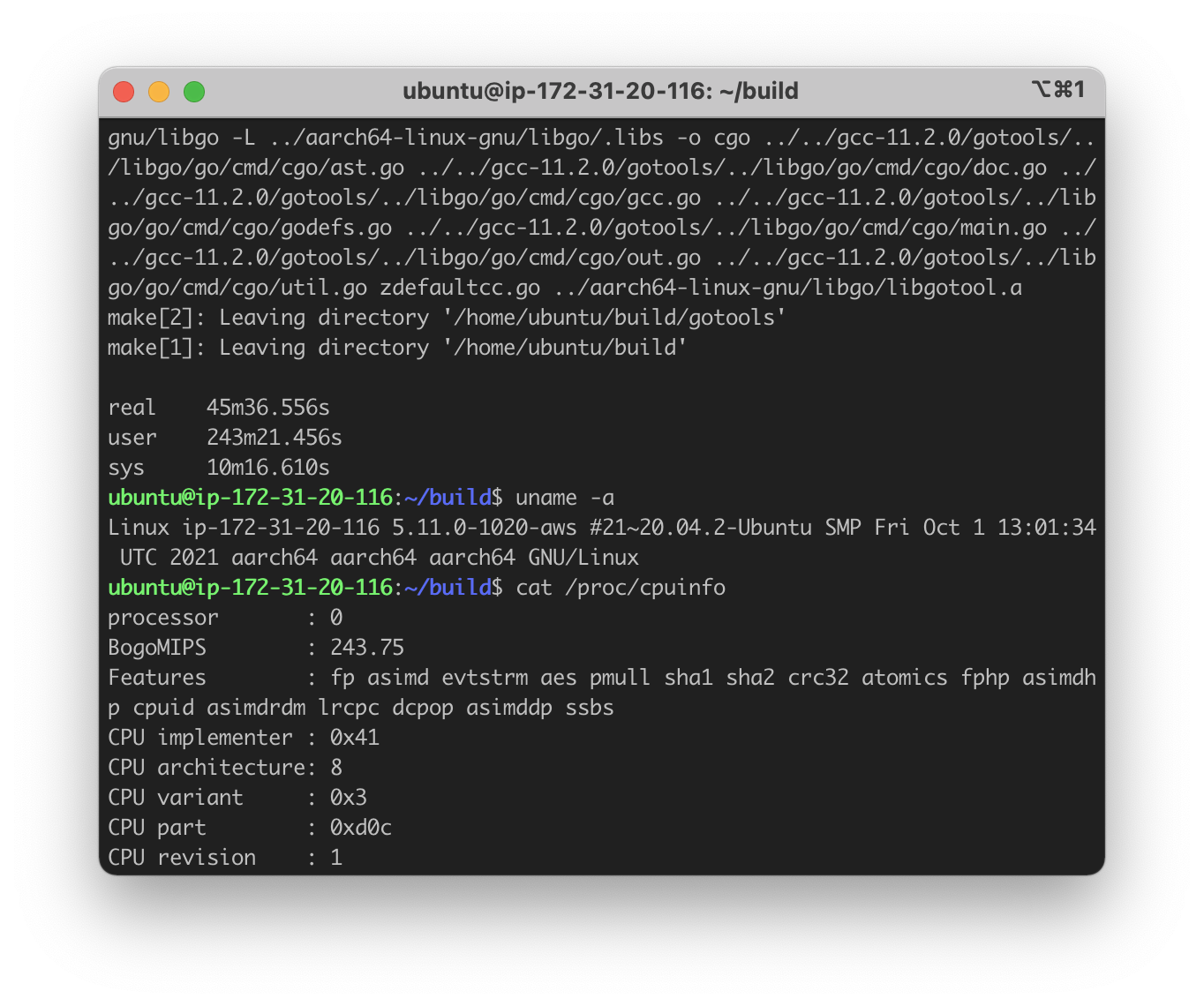
The hardware configuration on AWS c6g.2xlarge is just the stock one, which is 8 cores and 16 GB of RAM. The system image on the c6g.2xlarge machine is also ubuntu 20.04.
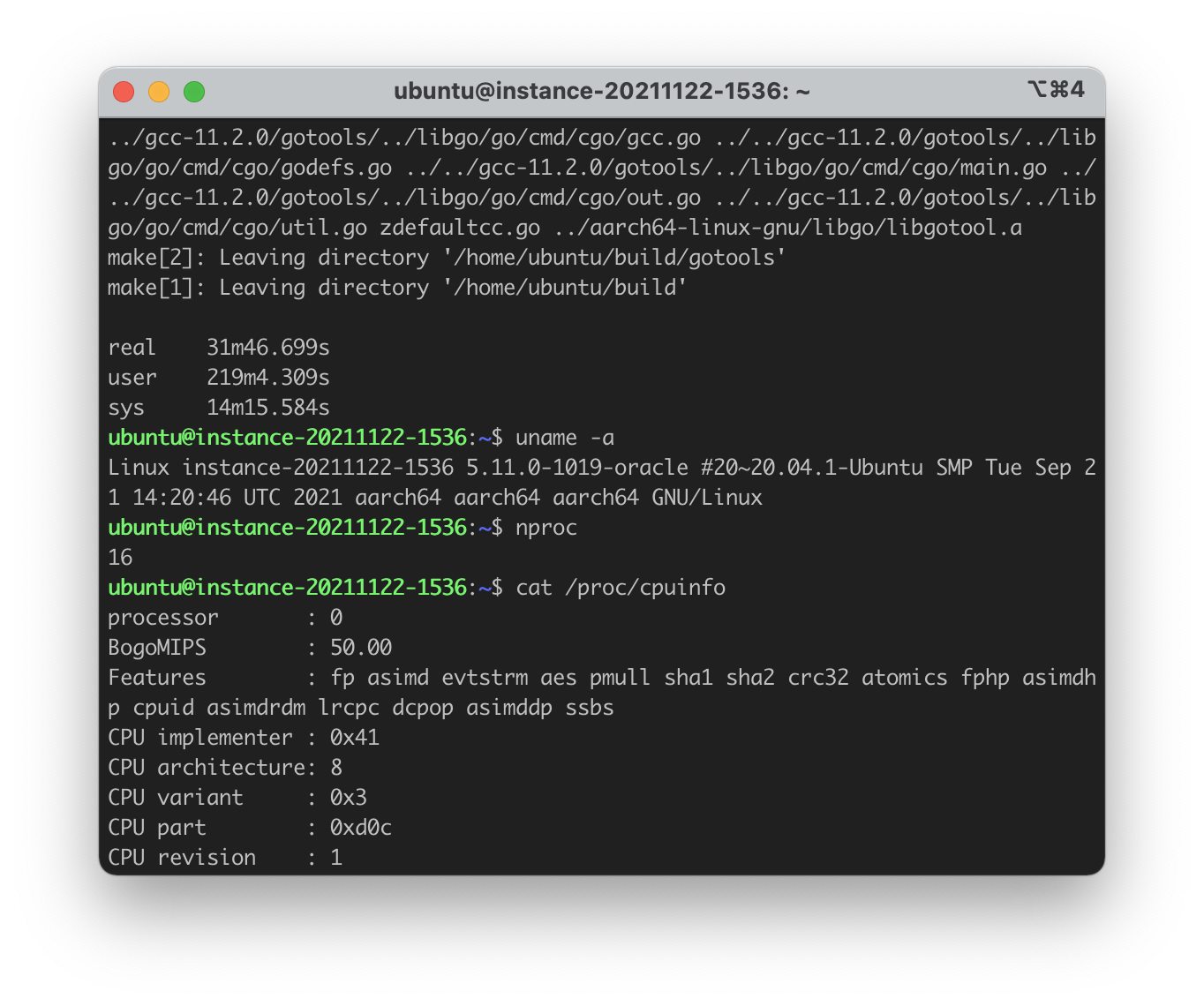
As for the Oracle Ampere (VM.Standard.A1.Flex), I tested three configurations:
- 4 CPUs, 24 GB of RAM
- 8 CPUs, 48 GB of RAM
- 16 CPUs, 96 GB of RAM
The first configuration is eligible for the Oracle Always Free Tier while the second configuration is meant to match the cores count with M1 Max and AWS c6g.2xlarge. The last one is the topped out spec (by default, but can increase the quota by upgrading to a paid account). The OS image used on these configurations is ubuntu 20.04 as well (image build is 2021.10.15-0).
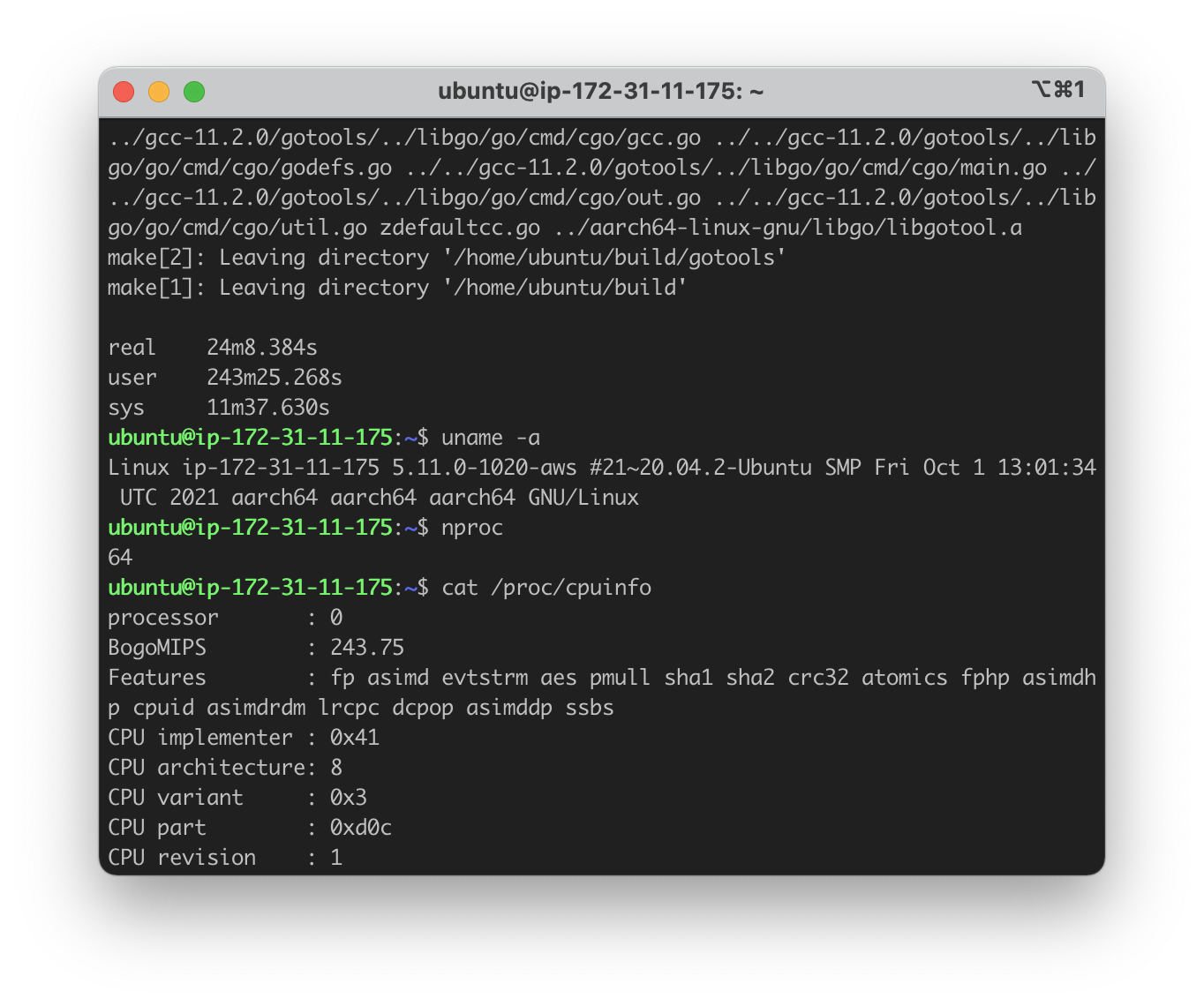
M1 Max completed the compilation in ~28 minutes while it took ~45 minutes and xx minutes for AWS c6g.2xlarge and c6g.metal respectively. The Oracle Ampere machines finished in ~68 minutes (4c), ~42 minutes (8c) and (16c). The precise results are shown in the table below.
| Machine | Cores | RAM | Cost | Compile Time (seconds) |
|---|---|---|---|---|
| MBP 14", M1 Max | 8@~3GHz | 14 GB | One Time, ≥$2,499.00 | 1697.344 |
| AWS c6g.2xlarge | 8@2.5GHz | 16 GB | $0.272/hr (~$204/m) | 2736.556 |
| AWS c6g.metal | 64@2.5GHz | 128 GB | $2.176/hr (~$1632/m) | 1448.384 |
| Oracle Ampere | 4@3GHz | 24 GB | Free Tier | 4109.323 |
| Oracle Ampere | 8@3GHz | 48 GB | $0.08/hr (~$30/m) | 2569.361 |
| Oracle Ampere | 16@3GHz | 96 GB | $0.16/hr (~$89/m) | 1906.699 |
As we can see that M1 Max is about 37.98% faster than the c6g.2xlarge machine.
The test script used is shown below
#!/bin/bash
export GCC_VER=11.2.0
export GCC_SUFFIX=11.2
export sudo="$(which sudo)"
$sudo apt-get update -y
$sudo apt-get install -y make build-essential wget zlib1g-dev
wget "https://ftpmirror.gnu.org/gcc/gcc-${GCC_VER}/gcc-${GCC_VER}.tar.xz" \
-O "gcc-${GCC_VER}.tar.xz"
tar xf "gcc-${GCC_VER}.tar.xz"
cd "gcc-${GCC_VER}"
contrib/download_prerequisites
cd .. && mkdir build && cd build
../gcc-${GCC_VER}/configure -v \
--build=aarch64-linux-gnu \
--host=aarch64-linux-gnu \
--target=aarch64-linux-gnu \
--prefix=/usr/local \
--enable-checking=release \
--enable-languages=c,c++,go,d,fortran,objc,obj-c++ \
--disable-multilib \
--program-suffix=-${GCC_SUFFIX} \
--enable-threads=posix \
--enable-nls \
--enable-clocale=gnu \
--enable-libstdcxx-debug \
--enable-libstdcxx-time=yes \
--with-default-libstdcxx-abi=new \
--enable-gnu-unique-object \
--disable-libquadmath \
--disable-libquadmath-support \
--enable-plugin \
--enable-default-pie \
--with-system-zlib \
--with-target-system-zlib=auto \
--enable-multiarch \
--enable-fix-cortex-a53-843419 \
--disable-werror
time make -j`nproc`